AI小芯片携手MCU拥抱低功耗SiP
发布时间:
硅谷AI芯片初创公司Femtosense与韩国微控制器制造商ABOV Semiconductor合作,打造了一款系统级封装产品,该产品采用Femtosense的低功耗AI加速器芯片组——稀疏处理单元(SPU),以及ABOV的Arm Cortex-M0+微控制器芯片组。两家公司都将在音频应用中推广和销售这款新的AI MCU,尤其是需要低成本、低功耗语音控制的消费电子产品和白色家电。
Femtosense首席执行官Sam Fok向EE Times表示,Femtosense与ABOV合作的部分原因是这家韩国公司与三星的联系。

Femtosense执行长Sam Fok
“如果你有三星家电,那么很有可能‘ABOV的’MCU已经投入使用,用于控制洗衣机电机、微波炉显示屏或其他设备,”他说。“将他们在供应链和供应商名单中的优势与我们带来的差异化AI能力结合起来是明智之举。”
Fok表示,基于嵌入式芯片的解决方案(实际上只是系统级封装(SiP)或多芯片模块(MCM))提供了与芯片为更大设计带来的一些相同的好处。
“这种方法的好处是,你可以非常轻松地重新混合这些产品,你可以将我们的SPU与‘ABOV]’产品组合中的不同微控制器相结合,”他说。“在这种情况下,我们将我们的SPU与非常低功耗、低成本的MCU配对,以创建最具成本效益的AI MCU之一。”
Fok表示,这可能是两家公司合作的几种基于芯片的组合中的第一个,并补充说,除了灵活性之外,芯片方法还能提供更好的产品上市时间。

Femtosense与ABOV的AI微控制器是一款包含两个chiplet的SiP。(来源:Femtosense)
“除了灵活性之外,你并不是在进行SoC练习,而是在制作一个全新的芯片,”他说,“这是一个封装练习,甚至不是一个非常先进的封装练习,因此你可以随着市场的发展快速扭转这些产品。AI市场仍在发展,人们希望在什么产品中拥有哪些功能,尤其是对于消费电子产品而言。”
“(多芯片模块)并不妨碍(未来)生产单个集成芯片,”他补充道,并指出,如果特定的MCU/NPU组合在经济和竞争力上看起来是正确的选择,那么该公司可以继续推进并制造SoC。
Fok说,作为一家初创公司,保持敏捷性很有帮助。初创公司需要能够快速响应客户的反馈,而将公司产品中的不同芯片组合在一起可能只需几个月的时间。这两个芯片也位于不同的工艺节点上。他指出,嵌入式闪存不适用于一些更先进的节点,这些节点需要高晶体管数量或高SRAM数量芯片,例如NPU。
“买家实际上并不关心——他们关心的是:它是否便宜,是否好用,是否具备能力。”
Femtosense之前提供芯片和IP,现在正在将小芯片添加到其产品组合中。据Fok称,坚持使用相同的底层架构有助于控制设计成本。虽然需要认证,但后续产品的速度会更快。
“市场存在既定的现状,你可以利用它,也可以尝试用自己的产品来打破现状,”他说。“许多终端客户都有完善的供应链,并且有非常严格的标准,这些标准在开始时可能对你不透明。这些因素有助于建立合作伙伴关系。”
还需要硅、IP和小芯片等实际工程方面的原因,比如在空间极其受限的应用中,只能容纳一个芯片。
“你可以说我不会提供该应用,也可以说只要它不会蚕食我们其他产品的需求,我不会无缘无故地拒绝业务,”Fok说。“在这方面保持灵活性是件好事。”
权重和激活稀疏性
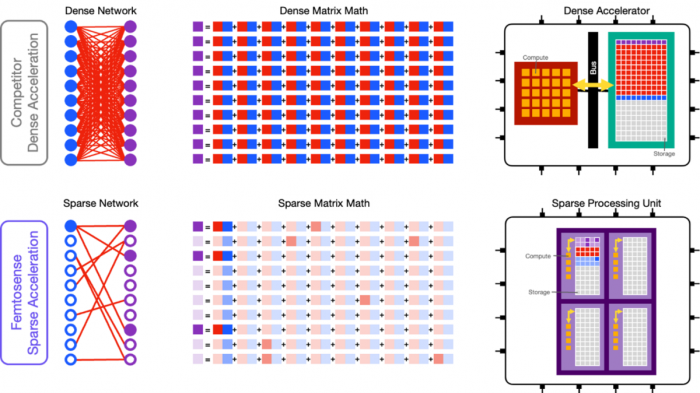
Femtosense的SPU旨在利用权重和激活的稀疏性。该团队主要来自神经形态计算领域,致力于提高算法和硬件效率。
Fok表示:“我们发现市场存在一个空白,没有人充分利用‘稀疏性’。市场上有一些产品在一定程度上利用了稀疏性—通常,问题是如何在使用脉动阵列的同时利用稀疏性,因此您将拥有大量结构,这可能会也可能不会让您充分利用这些优势。”
在设计SPU时,Femtosense选择了尽可能小的块大小,以便用户充分利用尽可能多的稀疏性。这包括对数据相关激活稀疏性的硬件支持(如果激活为零,则不必费心在下一个神经元中计算答案)。
稀疏权重矩阵可以在内存中压缩以节省空间,然后SPU的自定义指令可以处理压缩信息而无需解压缩。SPU支持将权重矩阵压缩高达90%。
Femtosense的稀疏化过程激励网络在训练期间考虑操作和连接的成本。
Fok表示:“量化可能只会使用无限可能性中的256个值。稀疏性就像在空间或时间中进行‘量化’,分别具有权重和激活稀疏性。我拥有所有这些可以使用的神经元和连接,也许我在训练期间需要它们,但在推理期间我不需要它们全部,所以我将激励网络将尽可能多的值归零,仅使用其中的一部分,然后在硬件中仅调动资源来服务这些区域。”
和量化一样,稀疏化也可能过度,从而降低预测准确性。但Fok坚持认为,合理利用稀疏化可以真正提高效率。“这需要测试才能找到正确的平衡,就像量化一样,”他说。
Femtosense希望利用权重和激活稀疏性将稀疏网络加速至100倍。这可能意味着在较小的硬件上运行较大的网络,或同时运行多个网络。(来源:Femtosense)
Fok指出,如果权重稀疏性(修剪)可以实现10倍,激活稀疏性也可以实现10倍,那么这些值可以成倍增加,从而实现100倍的能效提升。他表示,在实践中,客户已经能够在SPU的1 MB SRAM中以可接受的质量运行需要大约7 MB内存的应用程序,在某些情况下甚至可以减少占用空间以同时运行多个模型。
SPU专为音频和语音应用而设计(但支持所有时间序列传感器数据),具有三种精度模式-INT16激活、INT8权重、INT8激活和权重或INT8激活和INT4权重。Femtosense的软件工具可以帮助进行量化以及模型优化、稀疏化、修剪和编译。
Fok指出,SPU还可以非常高效地运行密集矩阵,因为SPU的架构最大限度地减少了数据移动并最大限度地提高了并行性。
“这是人们已有工作负载的简单入口,”他说。“然后,如果他们想运行两个可能不适合的工作负载,或者添加更大的模型以获得更多功能,或者通过更少的错误激活获得更好的性能,诸如此类的事情,那么[稍后]他们就应该花精力进行额外的微调或将稀疏性纳入训练模型。我们希望在人们已有工作负载的情况下,轻松采用现有的东西,同时解锁更多功能。”
SPU的原始计算效率为500 GOPS/W(在200 MHz下,具有INT4权重、INT8激活),但在最大稀疏度水平下可以实现有效50 TOPS/W。SPU芯片组有两个内核,每个内核都有四个独立的16路并行矢量处理ALU和1 MB SRAM。
Femtosense/ABOV AI MCU的工程样品现已上市,预计于2024年底实现商业量产。
(参考原文:Femtosense Combines AI Chiplet with MCU for Audio SiP,by Sally Ward-Foxton)